Data Science at UC San Diego
May 24, 2017 by Bradley Voytek
What is Data Science?I've been somewhat obsessed with this question for years now. In this post I outline my views, as well as the semi-consensus view being adopted here at UC San Diego.
As someone who's held the job title of Data Scientist, who teaches Data Science classes, and who is a Founding Faculty member of the Data Science Major and the new Data Science Institute, I take very seriously the idea that Data Science can and should be an independent, novel field of scientific inquiry. And that it will be a massively important one at that. My musings on this recently came to a head with the release of a White Paper I helped write for the UC San Diego Division of Social Sciences (detailed below).
Most critically, I am strongly of the opinion that Data Science does not just equal Machine Learning. This is an opinion I expound on below, but is nicely summarized by friend Josh Wills, Data Engineer at Slack:
Rule #1 of Hiring Data Scientists: Anyone who wants to do machine learning isn't qualified to do machine learning.
— Josh Wills (@josh_wills) February 18, 2017
Rule #2 of Hiring Data Scientists: You can get a data scientist to do anything if they believe that what they are doing is machine learning.
— Josh Wills (@josh_wills) February 18, 2017
There's a confluence of a lot of Data Science things happening at UCSD right now that make this document timely:
- UC San Diego recently received $75M from early Facebook employee and UCSD alumnus Taner Halicioglu to start a new Data Science Institute here.
- Fall 2017 will be the first year that the new Data Science major will be offered here at UCSD—a joint major between my home department of Cognitive Science with the departments of Computer Science and Math.
- On June 8 I'm hosting a two hour fireside chat with DJ Patil, former Chief Data Officer of the United States under Obama, former LinkedIn Data Scientist, co-coiner of the phrase "Data Scientist", and UCSD alumnus.
I've since taught that class three more times, and most recently it had 280 students. This quarter I'm teaching an entirely new upper-division version of that class—(COGS 108) Data Science in Practice—to about 420 students. (The syllabus for Introduction to Data Science is here; Data Science in Practice is here along with the public podcasts here as well as some tutorials on GitHub.)
The demand for the theory and skills of Data Science is skyrocketing, which I joke about in my lectures:
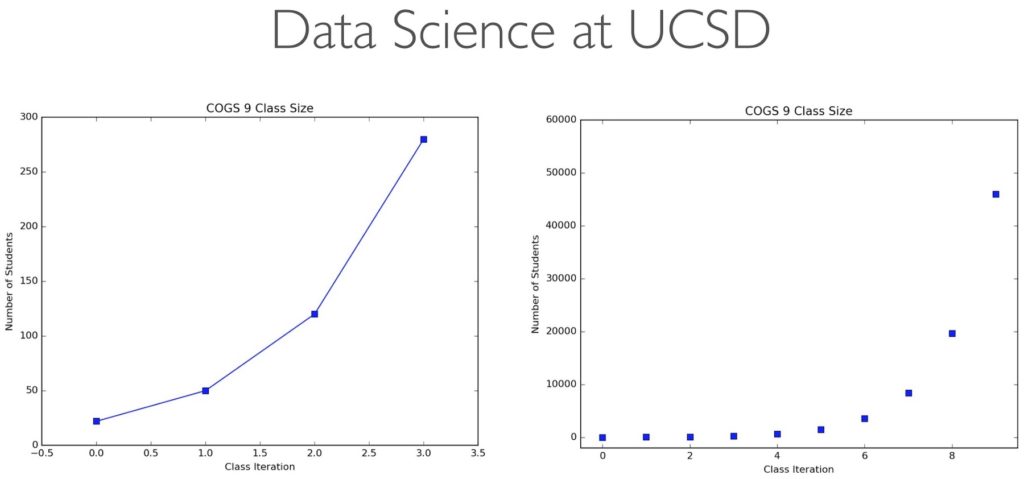
But joking aside, there are serious concerns that Data Science is a fad. This is Very Bad News when one is trying to establish a new major, Institute, and potentially even field!
Personally I'm of the opinion that Data Science is simply plummeting toward the hype cycle Trough of Disillusionment:
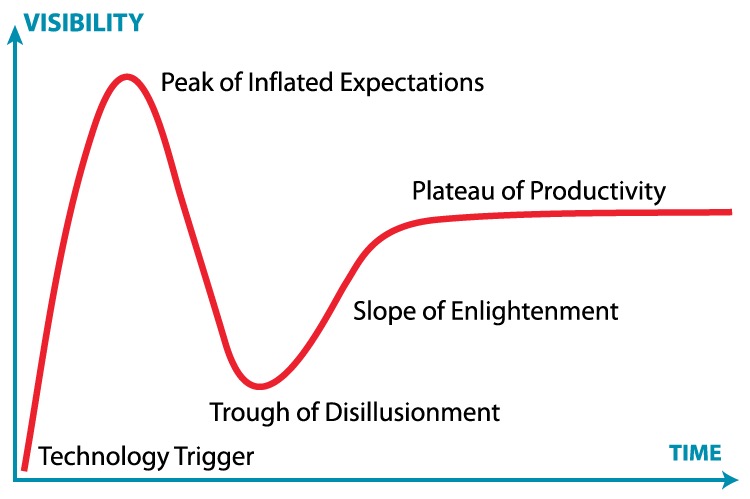
I consider this to be a good thing, as it's a time for moving past the hype and doing the boring academic work of carving a niche and laying the foundations for a new field. (See also, 50 years of Data Science by David Donoho.)
When I first began conceiving of Data Science as an independent field of scientific inquiry, I saw that New York University’s Initiative in Data Science website has a “What is Data Science?” page, on which it is stated that:
There is much debate among scholars and practitioners about what data science is, and what it isn’t. Does it deal only with big data? What constitutes big data? Is data science really that new? How is it different from statistics and analytics?
I believe that this ambiguity about the scope, aims, and distinctive characteristics of a Data Science discipline has (correctly!) given rise to skepticism.
But honestly, this skepticism strikes me as reminiscent of criticisms of Computer Science as a distinct discipline back in the 1950s, with some decrying it as “impossible that computers themselves could actually be a scientific field of study”.
I believe that the skepticism of Data Science is similarly misplaced, albeit understandable given the lack of clarity as to what Data Science is, what it can be, and what scientific and social problems are unique to the modern proliferation of massive amounts of contextual and personal data.
To address the general lack of clarity, we wrote a White Paper laying out what we believe are the core establishing questions that define Data Science, and lay the groundwork for what it can and should be. I recommend you read the whole thing (I'm proud of it!) but will highlight pieces here.
Foundational Questions in Data Science
- Why are some problems more amenable to purely data-driven approaches using generic learning algorithms than to domain-specific structure, or vice versa?
- What factors determine data quality with respect to a particular question?
- Can we ascertain a priori whether a particular question can be answered via a particular data source?
- Can we estimate the data requirements for adequate algorithmic performance in a given domain?
- When can training on synthetic data substitute for training on real-world data?
- How do we combine unstructured, data-driven machine learning algorithms with human domain expert knowledge?
- More generally, how can we design systems that integrate human intelligence with algorithmic data-science predictions, leveraging humans’ rich understanding of the world to improve predictions, and to help human decision-makers with algorithmic forecasts?
For a somewhat trite example, why does Google Translate work as well as it does without any hard-coded information about grammar, semantics, linguistics, etc.? (See The Unreasonable Effectiveness of Data by Halevy, Norvig, and Pereira).
There is a lot of room here for uniquely Data Scientific questions that do not neatly fit into Computer Science, Statistics, or the Social Sciences.
Regarding the latter, there are also many Data Scientific questions highly relevant to the Social Sciences.
Social Sciences and Data Science
- How does society balance the demand for data and individuals’ rights to privacy?
- Is it possible to develop provably anonymous data-gathering strategies?
- How can data-intensive organizations avoid perpetuating and reinforcing the inequalities inherent in data as algorithms and automation gain prominence in ever-more important aspects of modern life (e.g., 1, 2, 3)?
- How do we identify and anticipate challenges that some applications of data science might pose to the functioning of our democratic political, economic, and cultural institutions?
- How do we develop forms of data-literacy that foster collaboration across disciplines and generate awareness of the social, political and historical embeddedness of data and data infrastructures?
- As an educational institution, how do we promote data-literacy at all levels, from undergraduate education, broadly conceived, to even the data collection activities of the university itself?
In our White Paper we outline four paths within the new Data Science Major and Institute:
Data Engineering: The development of data architectures, algorithms, systems, etc. for capturing, storing and processing an exponentially increasing torrent of data. In industry, holders of jobs with this title are often tasked with establishing the data infrastructure necessary to make analytics and machine learning feasible.
Machine Learning and its Foundations: The mathematical and algorithmic tools for learning from data and their theoretical foundations, including questions such as which problems are more or less amenable to general purpose data-driven approaches, what are the sample, memory, time complexities of specific problems, inter alia.
Social Science Oriented Analytics: Although some AI/ML applications can be entirely machine-centered (a control system for a quadrocopter), most of Data Science aims to generate usable insights for humans about human behavior. Here the focus is on understanding how data science tools can be adapted to answer social science questions, how social science processes generate data and what this means for their analysis, how the results of large-scale machine learning can be made useful/understandable to people, how to seamlessly integrate human intelligence with machine learning in expert systems and for crowd-sourcing applications, and how expert knowledge interacts with machine learning approaches.
Data and Society: Beyond being a tool, Data Science itself should be an object of social science investigation. There is a need to bring cutting-edge research and applications in data science in conversation with democratic legal frameworks as well as forms of social analysis that examine how values get designed into technical systems. How can we develop provably anonymous data gathering and reporting strategies, balance the need for privacy with the demand for data, incorporate fairness and accountability into algorithms, and counter statistical/algorithmic discrimination to prevent data-driven approaches from perpetuating and reinforcing inequities? More broadly, we need to understand the social ethics required for a society where data science applications are pervasive.Finally, we close with what we believe are critical paths to success:
UC San Diego Division of Social Sciences Recommendations
Advancing Data Science as a distinct field of scientific inquiry and engineering, unifying faculty across many departments and divisions.
Improving data science education at the undergraduate, graduate, and faculty levels.
- Internships and portfolio building projects during education, including capstone projects. In particular, extramural projects wherein students work with outside companies, agencies, or labs.
- An interdisciplinary graduate program in Computational Social Science, at both the masters’ and doctoral levels
- Additionally, UC San Diego Data Science should place a special emphasis on Data Ethics.
- A civic good oriented summer program similar to the University of Chicago’s Data Science for Social Good Summer Fellowship program.
- University and community partnerships creating easy-to-use software tools for search, visualization, and analysis of big data for the lay members of the community.
But this is not a lone effort, and I would very much love to hear feedback from academics, professionals, and anyone else on the future of Data Science both here at UCSD and more broadly.